robots.txt 文件规定了搜索引擎抓取工具可以访问网站上的哪些网址,并不禁止搜索引擎将某个网页纳入索引。如果想禁止索引(收录),可以用noindex,或者给网页设置输入密码才能访问(因为如果其他网页通过使用说明性文字指向某个网页,Google 在不访问这个网页的情况下仍能将其网址编入索引/收录这个网页)。
robots.txt 文件主要用于管理流向网站的抓取工具流量,通常用于阻止 Google 访问某个文件(具体取决于文件类型)。
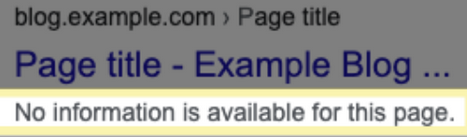
如果您使用 robots.txt 文件阻止 Google 抓取网页,有时候其网址仍可能会显示在搜索结果中(通过其他链接找到),但搜索结果不会包含对该网页的说明:

robots.txt文件怎么写
只有使用特定的语法和符号编写的robots.txt文件才能被正确识别,所以是需要遵循一定的语法规则的,但是不用担心,非常的简单,只有三个关键词和2个通配符。
下面是一个简单的例子:
User-agent: *
Allow: /seo/*.jpg$
Disallow: /seo/*User-agent
User-agent: *(定义所有搜索引擎)
User-agent: Googlebot (定义谷歌,只允许谷歌蜘蛛爬取)
User-agent: Baiduspider (定义百度,只允许百度蜘蛛爬取)
不同的搜索引擎的爬虫有不同的名称,比如谷歌:Googlebot、百度:Baiduspider、MSN:MSNbot、Yahoo:Slurp。
Disallow
Disallow:(用来定义禁止搜索引擎爬取的页面或路径)
比如:
Disallow: /(禁止蜘蛛爬取网站的所有目录 “/” 表示根目录下)
Disallow: /SEO/(禁止蜘蛛爬取SEO目录)
Disallow: /test.html (禁止蜘蛛爬取test.html页面)
Allow
Allow:(用来定义允许蜘蛛爬取的页面或路径)
比如:
Allow: /SEO/test/(允许蜘蛛爬取SEO下的test目录)
Allow: /SEO/test.html(允许蜘蛛爬取SEO目录中的test.html页面)
两个通配符
通配符 “$”
$ 通配符:匹配行结束符。
比如:
Allow: /seo/*.jpg$上面这段代码就是允许爬虫爬取SEO目录下所有jpg结尾的文件。
通配符 “*”
* 通配符:匹配0个或多个任意字符
Disallow: /seo/*上面这段意思是禁止爬虫爬取SEO目录下所有文件。
工具生成robots.txt
对于SEO小白来说,最好还是使用站长工具去生成robots.txt文件,防止规则写错,有时候真的是“一念天堂,一念地狱”的差别,要是robots.txt文件规则写错了,有可能会导致整个网站搜索引擎不收录的情况,所以在写这个文件的时候一定要认真,如果出现问题要想想是不是写错了规则,改完之后再到站长平台去提交新的文件。
作者:terry,如若转载,请注明出处:https://www.web176.com/news/promotion/7421.html
 支付宝
支付宝  微信
微信